Learning To Recognize Procedural Activities
with Distant Supervision
Xudong Lin Fabio Petroni Gedas Bertasius Marcus Rohrbach Shih-Fu Chang Lorenzo Torresani
Abstract
In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
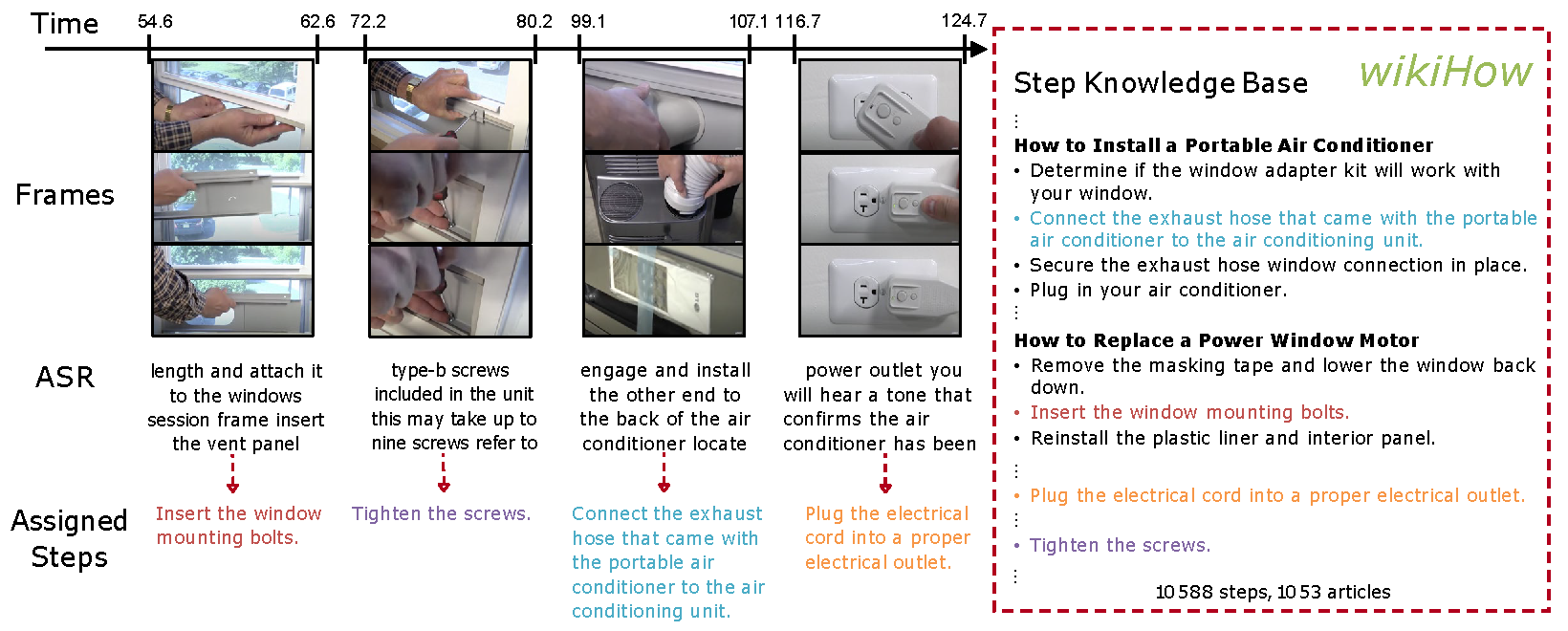
Figure 1. Illustration of our proposed framework. Given a long instructional video as input, our method generates distant supervision by matching segments in the video to steps described in a knowledge base (wikiHow). The matching is done by comparing the automatically-transcribed narration to step descriptions using a pretrained language model. This distant supervision is then used to learn a video representation recognizing these automatically annotated steps. This video is from the HowTo100M dataset.
Citation
@misc{lin2022learning,
title={Learning To Recognize Procedural Activities with Distant Supervision},
author={Xudong Lin and Fabio Petroni and Gedas Bertasius and Marcus Rohrbach and Shih-Fu Chang and Lorenzo Torresani},
year={2022},
eprint={2201.10990},
archivePrefix={arXiv},
primaryClass={cs.CV}
}